什么是好的预测?
预测就像朋友:信任是最重要的因素(你永远都不希望你的朋友对你撒谎),但在你值得信任的朋友中,你更愿意结识那些能告诉你最有趣故事的人。
我这个比喻是什么意思?我们希望预测 "好"、"准"、"精"。但这是什么意思呢?让我们理清思路,更好地阐述和想象我们希望从预测中得到什么。衡量预测质量有两种独立的方法,您需要同时考虑这两种方法--校准和清晰度--才能对您的预测性能有一个满意的了解。
预测校准
为简单起见,让我们从二元分类开始:预测结果只能有两个值,即 "真或假"、"0 或 1 "或类似值。
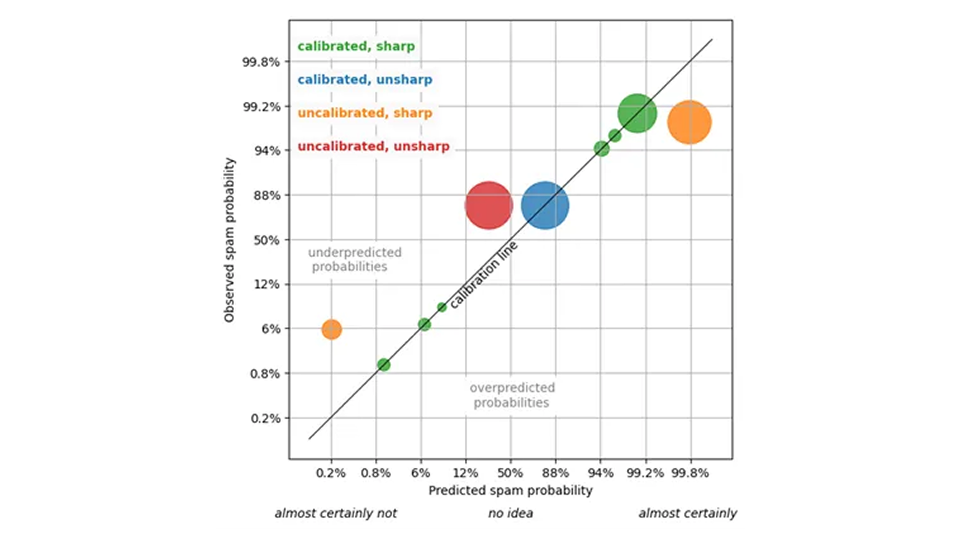
更具体地说,让我们来看看电子邮件,以及它们是否会被邮箱用户标记为垃圾邮件。预测系统会为每封邮件计算出该邮件被用户视为垃圾邮件的概率百分比(我们将其视为基本事实)。超过一定的阈值,如 95% ,电子邮件就会被放入垃圾邮件文件夹。
要评估该系统,首先可以检查预测的校准情况:对于那些被指定为垃圾邮件概率为 80% 的邮件,真正的垃圾邮件比例应该在 80% 左右(或至少在统计上没有显著差异)。对于那些垃圾邮件概率被定为 5% 的邮件,真正的垃圾邮件比例应该在 5% 左右,以此类推。如果是这样,我们就可以相信预测:所谓的 5% 概率确实是 5% 概率。
经过校准的预测可以让我们做出战略性决策:例如,我们可以适当设置垃圾邮件文件夹的阈值,还可以预先估计误报/漏报的数量(有些垃圾邮件会进入收件箱,而有些重要邮件最终会进入垃圾邮件文件夹,这是不可避免的)。
预测清晰度
校准是预测质量的全部吗?不完全是!试想一下,如果对每封电子邮件都进行总体垃圾邮件概率预测,即 85% 。这一预测非常准确,因为 85% 的电子邮件都是垃圾邮件或其他恶意邮件。你可以相信这种预测,它没有骗你--但它非常没用:您不能根据琐碎的重复声明 "这封邮件是垃圾邮件的概率是 85%"做出任何有用的决定。
一个有用的预测是对不同的电子邮件赋予截然不同的概率--你老板的电子邮件的垃圾邮件概率为 0.1% ,可疑的医药广告的概率为 99.9% ,并保持校准。统计学家把这种有用性称为锐度,因为它指的是预测结果分布的宽度:越窄,越尖锐。
非个性化预测总是产生垃圾邮件概率 85% ,是最大限度的不清晰。最大清晰度是指垃圾邮件过滤器对每封电子邮件只赋予 0% 或100% 的垃圾邮件概率。这种最大程度的敏锐性--确定性--是可取的,但却不现实:这种预测(很可能)没有经过校准,一些标记为 0% 垃圾邮件概率的邮件会变成垃圾邮件,一些标记为 100% 垃圾邮件概率的邮件会变成你重要伴侣的邮件。
最佳预测是什么?我们不想放弃信任,因此需要对预测进行校准,但在校准后的预测中,我们希望得到最准确的预测。这就是 Gneiting、Balabdaoui 和 Raftery 于 2007 年提出的概率预测范式(J.P.D.,2007 年)。R.统计学家Soc.B 69, Part 2, pp.243-268):最大限度地提高清晰度,但不要影响校准。 在保持真实的前提下,尽可能做出最有力的陈述。就像我们的朋友一样,给我讲最有趣的故事,但不要对我撒谎。对于垃圾邮件过滤器来说,最敏锐的预测值为:1% ,相当明显不是垃圾邮件的邮件为 99% ,难以判断的情况(应该不会太多)为中间值。