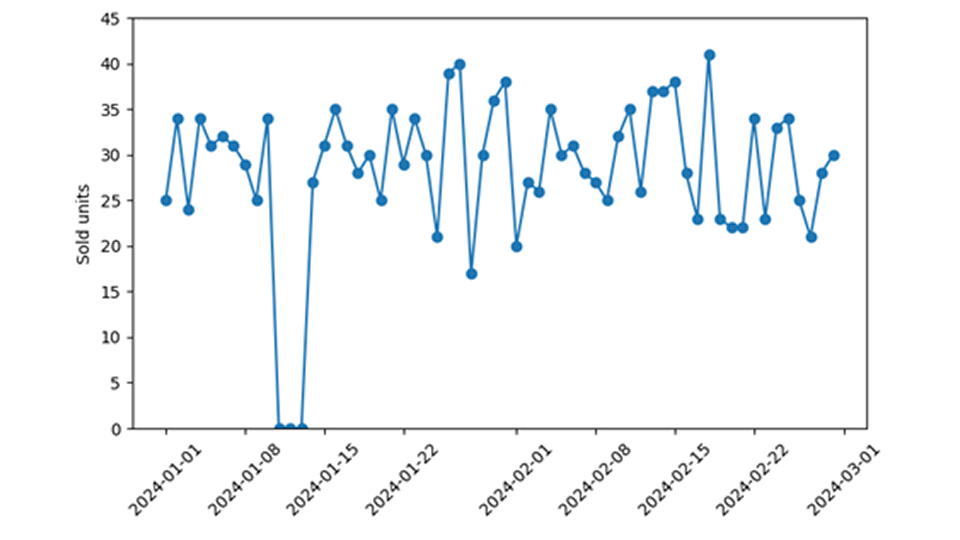
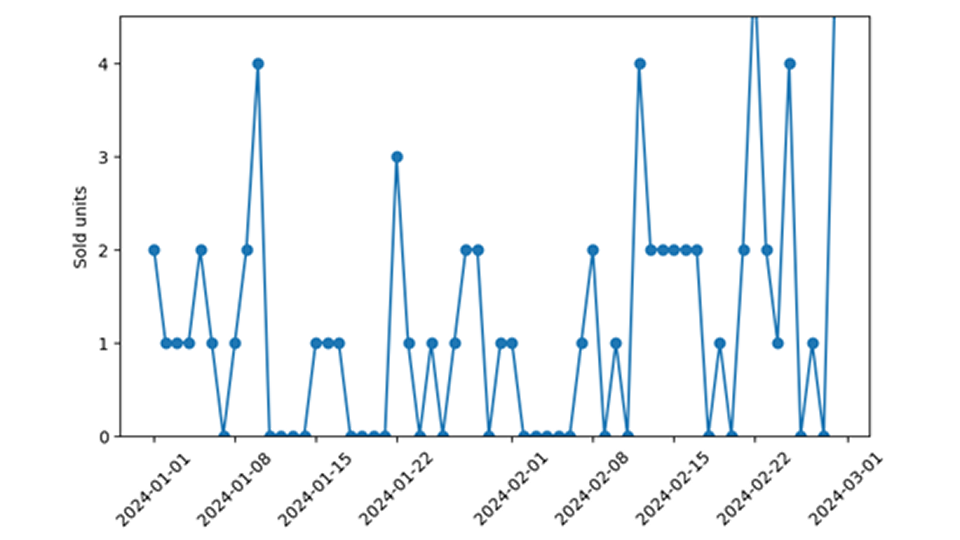
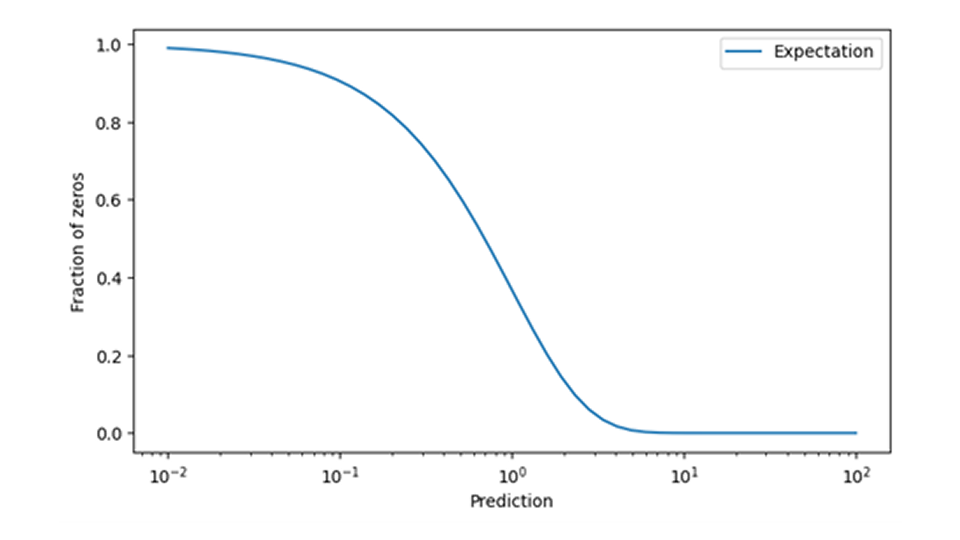
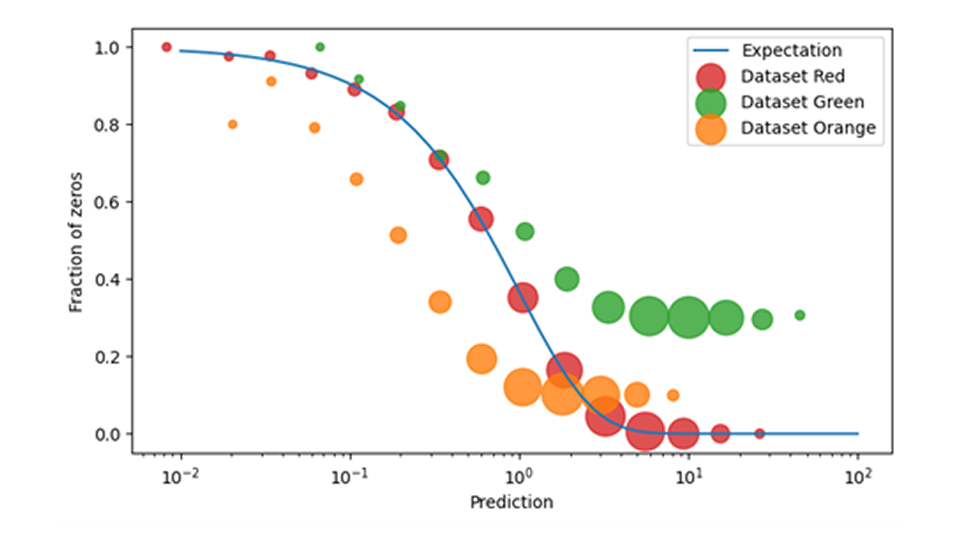
在零售业预测中,在训练和应用需求模型时需要特别注意零销售事件。很难事后查明,零销售事件是真的见证了某一天需求的消失(如 "没有人从货架上拿走该产品"),还是预测的产品根本没有上市(如 "该产品甚至没有摆上货架")。值得庆幸的是,通过比较预测的零销售概率和观察到的零销售事件频率,可以检查数据与预测模型的一致性。当这些数据不一致时,即观察到零销售额的次数比预测的多得多或少得多时,就诊断出了一个重大但明确的数据问题。
零是否存在,如果存在,有多少种存在方式?
数字 "零 "在人类的抽象能力中已经消失了很长时间,令人惊讶。不同的古代文化以不同的方式对待 "没有任何东西",科学史家至今仍在争论 "零 "作为一个符号是何时以及如何被发明出来并成为数学主流的一部分。例如,罗马数字中甚至没有零的符号,这可能是因为罗马人将数字用于会计,而不是算术。亚里士多德甚至否定了 "零 "是一个数字的概念--当你不能被它除尽时,它还有什么用呢?公元七世纪,印度数学家和天文学家婆罗门古普塔开始使用和分析书写的 "零",随后,"零 "传入汉语和阿拉伯语,并通过后者传入欧洲文化。
当然,您了解零,并能自如地使用它。因此,让我们把几个世纪以来的数学讨论快进到利用人工智能(AI)和机器学习(ML)应用预测零售需求的阶段。我在此认为,只有一种 "零 "是不够的。要正确描述零售业的销售额,至少需要两个不同的 "零 "概念。其中一个必须保留在训练数据集中,另一个必须删除。
一方面,产品可以上市并向公众提供:商店开着,收银机和其他一切都正常运转,但就是没有顾客愿意购买!在这种情况下,零销售事件反映了实际需求不足,消费者对该产品缺乏兴趣。理想情况下,我们的需求预测模型不会被这个零 "吓到",因为它预测到观察到零的概率并不小,但也是有限的。
真正的需求不足会导致需求为零,我想把它与可用性为零区别开来。后一种 "零 "仅仅是由于无法获得产品而引起的。客户甚至没有得到产品,即使他们想买,也没有机会(我们永远不会知道)。昨天,我并没有以 99 美元的价格卖出一部 iPhone,但这只是一种微不足道的说法,因为我甚至没有向任何人提供任何 iPhone。如果是我出价,我的期望价格适中,会引起相当大的需求,很可能会找到买家。我也没有在网上出售我提供的二手婴儿车--那信息量更大,是零需求。需求为零反映出该物品并不特别受欢迎(说得轻一点),而无法获得为零则与物品的真实需求无关。
买不到的原因有很多:最重要的是,库存可能被消耗殆尽--这时根本就没有东西可卖了。因此,在我们的数据中,有一栏精心策划的早间股票价值是非常好的。然后,我们可以重新使用本博文中介绍的方法。然而,我们遇到的往往不是这样的数据质量天堂:库存信息不可用,或者至少不完全可信。但是,即使整合了可靠的库存值,我们也不能完全确定货架上是否真的有这种产品--它可能被存放在里屋,商店经理可能已经决定今年提供这种产品的时间过早或过晚。
无法提供掩盖了真正的需求:要了解一件商品的需求量,我们需要提供它。我不知道一件带粉色洒花的绿色雨衣会引起多少需求,除非我把它摆上货架,贴上价格标签,然后提供给顾客。如果不提供产品,我只能假设需求,而无法衡量需求。
综上所述,我对 "零 "的概念有以下两种:零需求 "是一种行为良好的需求,它诚实地传达了一个信息(也许是欺骗性的),即货架上的产品并不受欢迎(顺便问一句:有人需要二手婴儿车吗?)和可用性-0,它隐藏了真实需求的所有可能信息--需求可能是 0、1、14 或 2 766。很明显,我们需要将需求量零纳入模型训练,但如果将可用性零误认为需求量不足,就会造成巨大损失。
.png%3Fh%3D480%26iar%3D0%26w%3D640&w=1920&q=75)